分布式数据库HBase的数据处理与存储服务
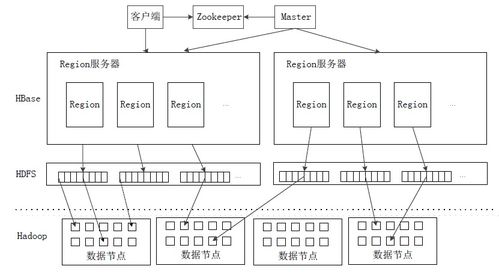
HBase是Apache Hadoop生态系统中的一个重要组成部分,是一种基于HDFS的分布式、面向列的NoSQL数据库。它专为处理大规模数据而设计,能够提供高可靠性、高性能的数据存储和实时访问服务。本章将围绕HBase的数据处理与存储服务展开介绍,涵盖其核心概念、数据模型、存储机制、处理流程以及典型应用场景。
HBase的数据模型以表的形式组织数据,表由行和列组成。每一行通过行键(Row Key)唯一标识,列则按列族(Column Family)分组存储。这种结构支持灵活的数据模式,便于存储稀疏数据。在存储方面,HBase利用HDFS实现数据的分布式存储,并通过Region分区机制将大表水平分割,分布到多个RegionServer上,以实现负载均衡和高可扩展性。
数据处理方面,HBase支持高效的读写操作。写入数据时,HBase先将数据写入预写日志(WAL)以确保持久性,然后存储到内存存储区(MemStore),当MemStore达到一定阈值后,数据会被刷写到HDFS上的存储文件(HFile)中。读取数据时,HBase通过Bloom过滤器、块缓存等机制优化查询性能,能够快速定位和检索数据。HBase还支持数据压缩、版本控制和过期数据清理,以提升存储效率和数据处理能力。
在分析层面,HBase常与MapReduce、Spark等大数据处理框架集成,支持复杂的数据分析和批量处理任务。例如,用户可以通过HBase的API或Hive等工具执行查询和聚合操作。应用方面,HBase广泛应用于互联网、物联网、日志分析、推荐系统等场景,如存储用户行为数据、实时监控信息等,以满足高并发、低延迟的数据访问需求。
HBase作为一种分布式数据库,通过其独特的数据模型和存储架构,为大数据环境提供了可靠的数据处理和存储服务。结合其与Hadoop生态的紧密集成,HBase在企业和研究领域发挥着关键作用,帮助用户高效管理海量数据并实现实时分析。
如若转载,请注明出处:http://www.jisudianzimiandan.com/product/30.html
更新时间:2026-06-19 04:10:29