Apache Hudi 统一批处理和近实时分析的现代化数据湖存储层
在数据驱动的时代,企业面临着处理海量数据并从中快速获取价值的挑战。传统的数据架构往往将批处理(处理历史、大批量数据)和流处理(处理实时、连续的数据流)割裂开来,使用不同的存储系统和计算引擎,导致了数据孤岛、处理复杂性和高昂的运维成本。Apache Hudi(Hadoop Upserts Deletes and Incrementals)应运而生,旨在解决这一核心痛点,为数据湖提供了一个统一的存储和服务层,无缝地桥接了批处理和近实时分析。
一、Apache Hudi 的核心定位与价值
Apache Hudi 是一个开源的数据湖表格式(Table Format),它构建在分布式文件系统(如 HDFS 或云对象存储 S3、OSS)之上。其核心价值在于将数据库的功能(如高效的更新、删除、事务控制)引入到大数据存储中,同时保持了数据湖的开放、可扩展和成本效益。
Hudi 实现了数据处理与存储服务的统一,具体体现在:
- 统一存储:同一张 Hudi 表可以同时服务于批处理作业(如 T+1 的 ETL、历史数据报表)和流处理作业(如实时仪表盘、事件驱动应用)。数据只需写入一次,即可被多种计算引擎(如 Apache Spark、Flink、Trino/Presto、Hive)以批或流的方式读取。
- 统一服务:Hudi 不仅存储数据,还通过其表服务(如压缩、清理、聚类)主动管理数据布局,优化查询性能。它提供了增量查询、快照查询等多种数据消费模式,让下游应用能灵活、高效地获取所需数据视图。
二、实现批流统一的关键技术
Hudi 通过其独特的数据组织模型和表管理功能,实现了这一宏伟目标:
1. 表类型与查询类型
* Copy-On-Write (COW):在写入时直接合并新数据与旧文件,生成新的数据文件版本。它提供了最佳的读取性能,因为读取时总是获取最新的、已合并的文件,非常适合查询频繁、对数据延迟要求较高的近实时分析场景。
- Merge-On-Read (MOR):新数据先写入到高效的增量日志文件中,查询时动态合并基础文件和日志文件。这极大地优化了写入延迟,支持更高的数据摄取吞吐量,同时仍能通过读时合并或后台压缩服务提供近乎实时的数据视图。
2. 增量处理范式
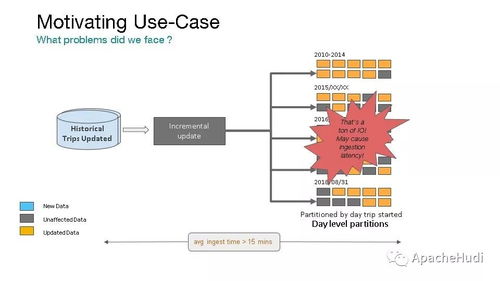
Hudi 引入了“增量查询”的概念。与传统的全表扫描不同,下游作业可以只拉取自上次检查点以来发生变化的数据记录。这从根本上改变了数据处理管道:
- 批处理:可以配置为定期的增量 ETL,只处理新数据,效率极高。
* 流处理:近实时分析管道可以持续消费增量数据流,实现分钟级甚至秒级的延迟。
这种模式统一了批和流的处理逻辑,许多管道只需编写一次,即可同时支持两种处理频率。
3. 事务与时间旅行
Hudi 通过时间轴(Timeline)管理所有对表的操作,提供了 ACID 事务保证。这意味着即使在并发写入和读取的场景下,数据的一致性也能得到保障。时间旅行能力允许用户查询某个历史时间点的数据快照,这为数据回溯、审计和基于时间点的分析提供了强大支持。
三、数据处理与存储服务的实践场景
场景一:近实时数据仓库与实时报表
交易、日志或 IoT 数据通过 Kafka 等消息队列持续流入。利用 Apache Flink 或 Spark Structured Streaming,以 MOR 表类型将数据低延迟地写入 Hudi 表。后台的压缩服务会定期合并日志文件以优化读取。BI 工具(如 Superset、Tableau)通过 Trino 直接查询 Hudi 表,分析师既能运行复杂的批量历史分析,也能在仪表盘上看到不断更新的近实时业务指标。
场景二:高效的增量数据管道
传统的 T+1 全量数据同步和计算任务耗时耗力。引入 Hudi 后,数据集成任务只需将每日变更(增、删、改)以增量方式同步到 Hudi 表。下游的数据质量检查、聚合计算、特征工程等批处理作业,全部转为增量处理模式,运行时间从数小时缩短到数十分钟,资源消耗大幅降低。
场景三:流式数据湖与机器学习
在推荐系统或风控场景中,模型需要最新的用户行为特征。用户实时交互数据被写入 Hudi 表,特征计算作业通过增量查询快速提取最新特征,更新特征库。训练和推理管道可以按需读取特定时间范围的全量或增量数据,实现了数据湖到特征存储的流式闭环。
四、与展望
Apache Hudi 通过将数据库的核心能力与数据湖的规模经济相结合,成功构建了一个统一、高效、可靠的数据存储与服务层。它打破了批处理与流处理之间的壁垒,使组织能够以更低的成本和更高的敏捷性构建现代化的数据架构。随着云原生和湖仓一体(Lakehouse)概念的普及,Hudi 凭借其对事务、更新删除和增量处理的卓越支持,正与 Iceberg、Delta Lake 等一起,成为构建下一代企业级数据平台的关键基石。对于任何寻求简化数据架构、统一数据服务并加速从数据中获取价值的企业而言,深入理解和应用 Apache Hudi 都将是一个极具战略意义的选择。
如若转载,请注明出处:http://www.jisudianzimiandan.com/product/57.html
更新时间:2026-02-24 05:06:11